What is Kafka?
Apache Kafka is a highly scalable and distributed event streaming platform that provides a robust foundation for building real-time data pipelines and streaming applications. It is designed to handle high volumes of data in a fault-tolerant and scalable manner, making it an ideal solution for organizations dealing with large-scale data processing. At its core, Kafka allows for the efficient and reliable transmission of data streams between systems and applications. It provides a publish-subscribe messaging model where producers publish records to topics, and consumers subscribe to these topics to process the records in real-time. This decoupling of data producers and consumers enables asynchronous and parallel processing, ensuring high throughput and low latency. One of the key strengths of Kafka is its ability to guarantee fault-tolerance and data durability. It achieves this by replicating data across multiple brokers, forming a distributed and fault-tolerant cluster. This architecture ensures that data is safely persisted and replicated, even in the face of hardware failures. Kafka's versatility extends beyond messaging. It serves as a powerful platform for building real-time data integration, stream processing, and analytics pipelines. With its rich ecosystem of connectors, frameworks, and tools, Kafka enables seamless integration with various data systems, including databases, data lakes, and analytics platforms. Moreover, Kafka provides strong ordering and message retention guarantees, allowing for reliable event sourcing and replayability of data streams. This makes it an excellent choice for building event-driven architectures, microservices, and applications that require accurate and consistent data processing. In summary, Apache Kafka is a high-performance, fault-tolerant, and scalable event streaming platform that enables organizations to build robust and real-time data pipelines. Its versatile features, along with its strong ecosystem, make it an indispensable tool for modern data-driven applications and architectures.
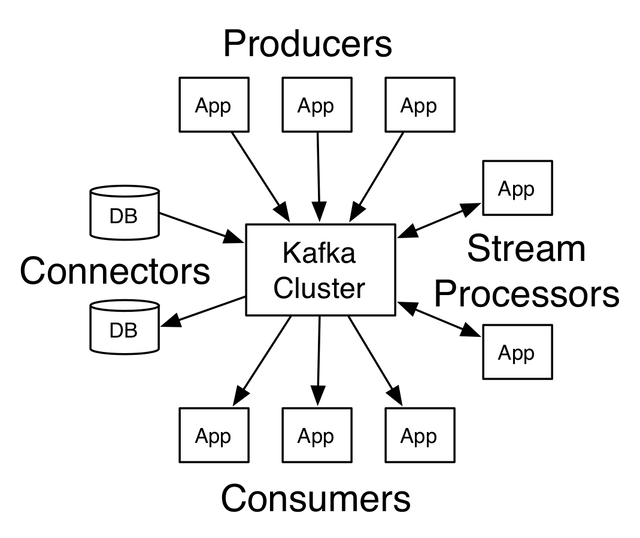
How does Kafka work?
Kafka is a distributed system that consists of multiple brokers, each of which is a server that stores and manages data. Brokers are organized into clusters, which are groups of brokers that work together to provide fault-tolerance and scalability. Each broker in a cluster is assigned a unique ID, which is used to identify it within the cluster. Brokers communicate with each other using the Kafka protocol, which is a binary protocol that defines how messages are sent and received. The Kafka protocol is designed to be efficient and lightweight, allowing for high throughput and low latency. Kafka uses a publish-subscribe messaging model, where producers publish records to topics, and consumers subscribe to these topics to process the records in real-time. Topics are logical categories that are used to organize records. Each topic is divided into partitions, which are ordered and immutable sequences of records.
How do I use Kafka?
Kafka is a powerful tool that can be used for a variety of purposes, including messaging, data integration, stream processing, and analytics. It can be used as a messaging system to build real-time data pipelines and applications. It can also be used as a data integration platform to connect various data systems, such as databases, data lakes, and analytics platforms. Kafka can also be used as a stream processing engine to process data streams in real-time. Finally, Kafka can be used as an analytics platform to perform real-time analytics on data streams.
Main features of Kafka
Scalability and High Throughput
Kafka is designed to handle massive amounts of data and support high message throughput. It can scale horizontally by distributing data across multiple brokers, allowing organizations to handle increasing data volumes without sacrificing performance.
Fault-tolerance and Durability
Kafka provides built-in fault-tolerance mechanisms by replicating data across multiple brokers in a cluster. This ensures data availability and durability even in the event of hardware failures. By storing data on disk, Kafka enables reliable message persistence, allowing messages to be stored and replayed as needed.
Pub-Sub Messaging Model
Kafka follows a publish-subscribe messaging model, where producers publish messages to specific topics, and consumers subscribe to these topics to consume the messages. This decoupling of producers and consumers allows for asynchronous and parallel data processing, enabling real-time data streaming and event-driven architectures.
Real-time Stream Processing
Kafka offers seamless integration with popular stream processing frameworks like Apache Storm, Apache Flink, and Apache Spark. This enables developers to process and analyze streaming data in real-time, enabling use cases such as real-time analytics, fraud detection, machine learning, and more.
Extensive Ecosystem and Connectors
Kafka has a thriving ecosystem with a wide range of connectors and integrations. It supports connectors for popular data systems like databases, message queues, and data lakes, allowing seamless data integration and interoperability. Additionally, it provides a variety of client APIs and libraries for different programming languages, simplifying the development and integration process.